
Or: Why everyone cares about agents
How much is it worth to solve fusion energy? Or to cure cancer, double human lifespan, or end climate change? Any of these are worth trillions of dollars – if only there was someone to pay! The Magic Promise of inference-time compute is that we can soon pay to solve any of these problems, by adding agentic capabilities to our models.
Scaling laws
These and other charts from the same OpenAI paper, Scaling Laws for Neural Language Models, represent the most consequential research results this decade in AI:
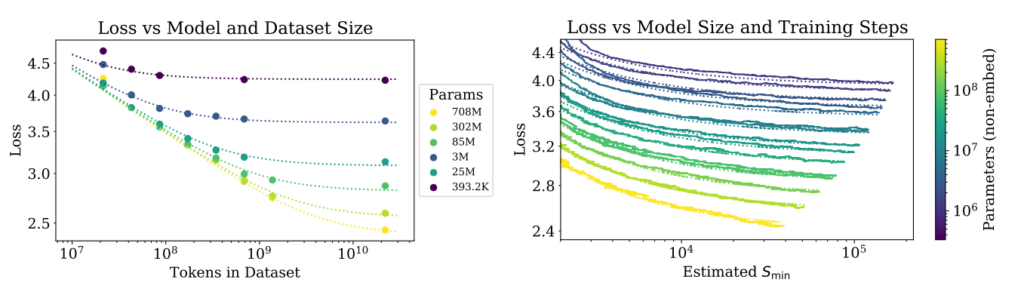
The conclusion of the paper is that spending more on data and hardware leads to a better model. This fact has dominated the last few years of technology as the major labs all attempt to outdo each other to train larger models. The vibe from researchers, executives, and venture capitalists is that there is probably room for one more generation of larger model; there may not be two. The scaling laws represented by these charts will bottom out. We need another strategy to improve model performance.
o1-preview’s Magic Trick
LLMs like GPT-4o or Claude Sonnet 3.5 can accomplish just about any task to process language. However, the one thing LLMs are famous for not being able to do is symbolic reasoning. The memes started with simple arithmetic, then moved on to counting letters in words. Algebra is a good example of symbolic reasoning, requiring that you manipulate the symbols into new positions and keep track of what operations you are performing. Symbolic reasoning is simply not how LLMs work.
For the Humanity’s Last Exam challenge (which pays for problems AI cannot solve), I created a brand new symbolic reasoning task:

GPT-4o, Sonnet 3.5, and Gemini 1.5 Pro bombed on this, but look at how o1-preview worked on it:

Notice how it has turned “fancy autocomplete” into a logical, step-by-step sequence of symbolic reasoning! Although o1 hides it, if you could see the actual reasoning output, you would see a much more detailed set of steps even within this very simple sequence. OpenAI realized that symbolic manipulation, the Achilles heel of LLMs, could be achieved if you structure the LLM’s output as tiny steps of reasoning.
OpenAI believes that they have discovered the secret to scaling beyond the limits of model sizes. Instead of continuing to increase model training time and data, they will spend more time having the LLM produce these reasoning steps after the user submits a prompt. There’s no theoretical limit for capability of a model if you give it enough time to do its reasoning.
Agents enabling inference-time compute
That sounds perfect, but there’s a catch: so far, reasoning decoheres after some amount of time. Either it loses track of what it was doing, starts repeating the same step continuously, or just starts outputting gibberish. There may not be a theoretical limit, but there’s a very real practical limit on LLM runtime. While we can’t see it directly, o1-preview is limited to reasoning for a minute or two and a few thousand tokens. This matches the experience of everyone else that has tried similar tricks.
The most important benchmark now is how long a model can reason before decohering. This is because if a model could reason for days and months, it could figure out how to make fusion work. There are a couple of features of agents that we describe as “agentic capabilities” that can help a great deal:
- Keeping a memory of goals in an external database
- Having several instances of the model work together
Keeping the overall goal and current goal in an external database can help keep the model’s reasoning on track. If it gets stuck or confused at any point, it can retrieve its unalterable goal. It can use this to restart its reasoning on a new path.
Having multiple instances of a model all work together on different aspects of a task is often called multi-agent. This is another way to break down the problem into smaller tasks that can be completed before the model decoheres. Each instance is given a different sub-goal, orchestrated by a primary instance. This helps for large problems for another reason, which is that we may be at the limit of how large and successful any single model instance can be as we exhaust the current scaling laws.
The resulting pattern of memory, external tool use, and multi-agent communication is most of my definition of an agent.
Dario Amodei, CEO of Anthropic, described the likely future as a “country of geniuses in a datacenter” that will solve many world problems just by reasoning about them long enough. It is plausible that this agent pattern combined with one more model generation is what will enable the cure for cancer and cost-effective carbon capture.
Much credit for this post and my thinking about inference-time compute goes to this essay from Aidan McLaughlin, AI Search: The Bitter-er Lesson.





