
Previous post | All posts in series
I just finished plugging in semantic (similarity) search to The Archive. Batching calls to index 20MB of embeddings at a time and parallelizing into three threads was the sweet spot for me, only taking 8 hours to index all Wikipedia embeddings. When I went to test it for the first time, I got hilariously bad results. Instead of paragraphs semantically related to “why did communism fail in China” I got paragraphs identifying the children’s names of obscure celebrities. And a formula for Nitrous Oxide!
After a bunch of debugging, I thought to check how many records were in my embedding database: only 2 million out of an expected 80 million! I think that somewhere after restarting from checkpoint I had a call to the delete() method.
But this is OK; I wanted to get to testing and evaluation next anyway. Catching issues like “dropped most of the database” immediately would at least save me debugging time! Functional tests are one thing, but what has me excited is performing LLM tests. We certainly do this in Copilot for Microsoft 365, but there is very little open source code evaluating LLM output. See these tweets from the inventor of the term “prompt injection” and multiple cool AI projects Simon Willison:
It’s hard not to conclude that diligent eval authorship is vanishingly rare at the moment, are we really all still hacking away at these things on vibes alone?
Let’s not hack away on The Archive on vibes alone; let’s evaluate our code.
The need for evals

In the Powerball lottery drawing this week, 4/6 numbers were odd. Even more telling, 4/6 of the numbers are prime! From this we can surmise that next week’s Powerball will be mostly prime numbers.1
Herein lies the type two gambler’s fallacy. When using an AI and we get a good result, we may believe it was because of something in our prompt. But it could just as easily be a fluke. Quite famously, LLMs are non-deterministic (true in practice, at least). This is why serious people are not worried about whether AI can determine whether 9.9 or 9.11 is greater or the number of ‘r’s in “strawberry” in isolation. We need hundreds if not thousands of tests in order to make any conclusions.
I expect The Archive is going to have a complicated reasoning loop with multiple system prompts. It’s already up to four LLM calls, and there’s a lot more that I want to do. But I have no chance of successfully making all those future updates if I don’t have great evals running frequently. Fortunately for me, there are tools that can help.
Generating Tests
Usually a problem with testing something hundreds of times is getting good test data. But LLMs are awesome at this. Once you work out how to correctly phrase the instruction, you’ll get an endless supply of test data.
The Archive is all about querying Wikipedia, and so the first thing I want to evaluate is accurate retrieval. I thought about using essay questions and answers, but instead I’m first going to start with simple facts. Simple facts like numbers and obscure names are a good test here, because they are least likely to be memorized in the model weights. If The Archive responds with the correct date or detail, it’s very likely it was in the RAG data.
This shouldn’t be too hard. We just need to programmatically get a few dozen Wikipedia articles and ask an LLM to generate questions with factual answers from them. These questions and answers need to get written out to a file in a particular format that the LLM may mess up, so we’ll need some error-handling as well.
Follow along with my Github repo, commit 17f9a…
Choosing a test framework
It wouldn’t be too complicated to run these tests with a generic test framework, like pytest. But I think we’ll gain some advantages if we choose a test framework designed for this problem. For example, it would be great to review answers from two system prompts side-by-side. Usually this would be automated, but it will help to be able to review manually to debug and also get a feel for how the answers are turning out. It will also come in handy as we start evaluating tone or handling multiple turns of a conversation.
DSPy is very popular for LLM apps. I’ve taken a look, and it would work here too. But it also does a lot of other things that I’m not sure I want to get into. It seems like it would be a big lift to get started. On the other hand, I found Promptfoo. This is designed only for evaluating LLMs, and its test definitions are very clean. Here’s my first test definition:
providers:
- id: "python:app_test.py"
config:
pythonExecutable: .venv/Scripts/python.exe
tests:
- vars:
inquiry: "when did Donatien Alphonse François write Juliette?"
assert:
- type: icontains
value: "1797"Subset of src/Test/promptfooconfig.yml
This is simply looking for a string in the output, but Promptfoo supports evaluating similarity or having another LLM evaluate the answer. I expect to use that later.
Integration pains
It took me longer than I wanted to get Promptfoo integrated. But at least I learned a lot!
- Using JSON in a prompt causes difficulties with LangChain prompt templates. In python, an f-string is one where you can insert variables. Those variables are marked with curly braces, which conflicts with JSON curly braces. LangChain seems to have a bug in some circumstances when you start escaping curly braces. The workaround I developed after a few hours of trying to get parsing to work is to use square brackets instead, then replace them in my code later. Fortunately the model doesn’t mind producing “JSON” with square brackets!
- The model I’m using, Phi-3.5-mini, likes to take the few-shot examples I’ve given and repeat them in its output. I just find-and-replaced these rows.
- I also had to drop any questions where the answers were more than 3 words, as they would be hard to string match when running the evals.
- JSON is more frequently represented in multiple line objects than JSONL, and the model often did that instead. I simply dropped those rows. Across all these errors, I am left with a little under half of the questions I asked for, but this is still plenty.
- One test run of 113 questions takes about an hour. I may be able to get this down to about 30 minutes through optimizations, but I may have to learn to be patient. I don’t want too few tests or I’ll be back to hacking away based on vibes.
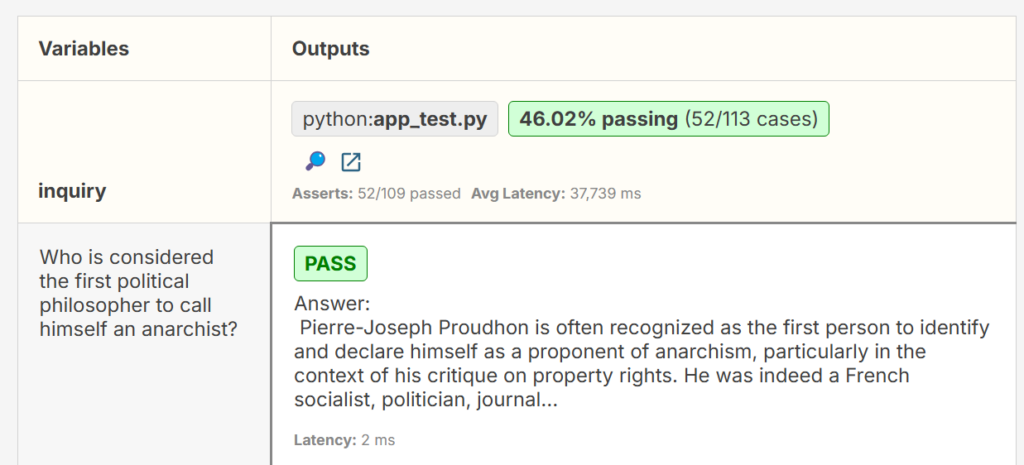
My first test pass of The Archive with all Wikipedia loaded is pretty bad, with a 46% success rate. I’m going to need to get more clever in the reasoning and RAG steps. Now with an eval suite, I’m ready to tackle it!
- These are not this week’s Powerball numbers. I just found an image online. ↩︎





